We always talk about clustered index, non-clustered indexes, heaps etc. as they are quite essential for enhancing the database performance. In this blog post I will demonstrate, how does SQL Server store the data in physical pages in case of Heap and Clustered Index.
What is Heap?
As explained in my previous blog (Understanding SQL Server indexes- Heap table vs Clustered Index), Heap is a table without any clustered index. It means data gets stored in 8k pages randomly without any linkages between the pages.
 Let’s create a heap table and insert some data from Person.BusinessEntity table:
Let’s create a heap table and insert some data from Person.BusinessEntity table:
CREATE TABLE [dbo].[Demo_BusinessEntity]( [BusinessEntityID] [int] NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL ) ON [PRIMARY] GO INSERT INTO dbo.Demo_BusinessEntity ( BusinessEntityID , rowguid , ModifiedDate ) SELECT BusinessEntityID , rowguid , ModifiedDate FROM Person.BusinessEntity GO
We have now inserted the data in heap so let’s check the page level and page count with the help of dmv.
SELECT page_count , index_level AS Page_level , record_count , index_type_desc FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('Demo_BusinessEntity'), NULL, NULL, 'Detailed')
We can see in below output that it is showing page count, record count, Index type and Page level (0 means it doesn’t contain any other level as showed in above image)
![]()
Let’s check the pages allocation using below dmv:
SELECT allocated_page_page_id , next_page_page_id , previous_page_page_id FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Demo_BusinessEntity'), NULL, NULL, 'Detailed') WHERE page_type_desc = 'DATA_PAGE'
We can see in below output that pages are not linked with each other (there is no pageid in next and previous column):

It proves that SQL Server stores the data in random pages in case of Heap table. Now I will show, how does SQL Server store the data in case of clustered index.
What is Clustered Index?
Data gets stored in B-trees. Every page in this B-tree is called an index node. The top-most node of this tree is called the “root node” and the bottom level of the nodes is called “leaf nodes” and any index level between the root node and leaf node is called an “intermediate level”.
The leaf nodes contain the data pages of the table in the case of a cluster index. The root and intermediate nodes contain index pages holding an index row. Each index row contains a key value and pointer to intermediate level pages of the B-tree or leaf level of the index. The pages in each level of the index are linked in a doubly-linked list (doubly linked list means, these pages contain the address of next and previous both the pages).

Coming back to demo, let’s create a clustered index on Demo_BusinessEntity table.
CREATE CLUSTERED INDEX CL_BusinessEntityID_BusinessEntity ON dbo.Demo_BusinessEntity (BusinessEntityID)
Now Clustered Index is created on the table, so it means data should be sorted physically on the basis of BusinessEntityID column. Let’s run dmv’s to see the changes:

We can see two level of pages, Page level 1 is Root node, which has 96 records as leaf page count and second level of pages (page level =0) are leaf pages where we have 96 pages and they hold 20K records as actual data.
Now, let’s check the page allocation using following query:
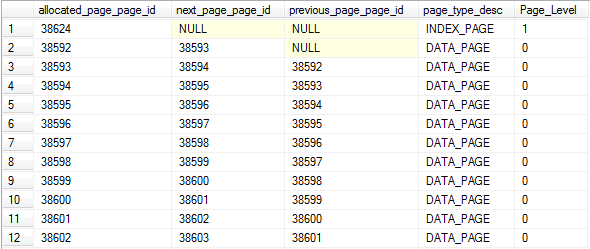
SELECT allocated_page_page_id , next_page_page_id , previous_page_page_id , page_type_desc , CASE WHEN page_type_desc = 'Index_page' THEN 1 ELSE 0 END AS Page_Level FROM sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('Demo_BusinessEntity'), NULL, NULL, 'Detailed') WHERE page_type_desc IS NOT NULL AND page_type_desc IN ( 'DATA_PAGE', 'Index_Page' ) ORDER BY CASE WHEN page_type_desc = 'Index_page' THEN 1 ELSE 0 END DESC , allocated_page_page_id ASC
You can see in following output, first page is root node so it doesn’t contain next and previous page. 38592 page id is first leaf page which holds its next page id, and subsequent page (id 38593) holds next and previous both the page ids. This is the reason we call it doubly linked list.
Let’s check what has SQL Server stored inside the root node with following query (provide your database name and page number you want to read)
DBCC PAGE ('AdventureWorks2012', 1, 38624, 3) WITH TABLERESULTS
We can see in following output that it holds child page ID and actual key as pointer.

We can see in above output that PageID-38594 holds the data for BusinessEntityID from 437 to 654. Let’s read the leaf page to see the actual data (all columns and their respective value).
DBCC PAGE ('AdventureWorks2012', 1, 38594, 3) WITH TABLERESULTS
You will get a large number of rows, but I am only picking the rows for BusinessEntityID 437 and 654 (first and last).

You can see in the image that all the three columns are stored in the index with actual values.
This is how Clustered index works in the background and this is the reason, it improves the performance of the queries as SQL knows where it has to go to pick the values. In case of heaps, SQL doesn’t hold this information and it has to scan the whole table to find the required rows.
Any query or feedback, please leave the comment. Thanks

Very Well explained.. 🙂
LikeLike
Thanks for the article..nicely explained…specially with use of demo and showing how data get stored at the page levels in heap n clustered index. Made things quite easy to understand.
LikeLike
Very well explained.. A must read for those who are looking to learn about SQL server indexes..
LikeLike
I and my buddies came analyzing the good suggestions from your web page and so quickly got an awful feeling I had not expressed respect to the blog owner for them. All the guys were definitely for that reason happy to read through them and have in effect surely been enjoying them. Many thanks for actually being so considerate and then for settling on these kinds of terrific areas most people are really eager to discover. Our sincere regret for not saying thanks to sooner.
LikeLike
Thanks guys for your feedback and I am glad you liked the blog, I will share a blog on non-clustered and unique indexes shortly.
LikeLike
Wow! This can be one particular of the most helpful blogs We’ve ever arrive across on this subject. Basically Great. I am also a specialist in this topic therefore I can understand your hard work.
LikeLike
Stumbled upon this while debugging one of the issues I was working on. I can gladly say it helped me find a way out of it. Thanks.
LikeLike